Subtotal ₹0.00
Sometimes, one might want to try out a new form of writing.
A more understanding, elegant and poised style, using the rhythms and tempo of the English language to present a piece of writing in an art form.
Depicting a whole story, article or even a book in a new art style could be a big risk – what if it doesn’t work? A blog post, on the other hand, is quick to write and even publishing is free: if it fails, guys you’ll not lost much. Blogging gives you the azadi to experiment, to try out something new.
The robots.txt file plays a crucial role in search engine optimization (SEO) by guiding search engines on which parts of a website they should or should not crawl and index. This file is placed in the root directory of a website and provides instructions to web crawlers, also known as search engine bots or spiders, about which pages or sections of the site should be accessible for indexing and which ones should be avoided.
Here’s why the robots.txt file is important for SEO:
Control Over Crawling: The robots.txt file allows website owners to control how search engines interact with their site. By specifying which parts of the site should not be crawled, you can prevent sensitive or duplicate content from being indexed, which can help ensure that only valuable and relevant content is shown in search results.
Preventing Indexation of Private Content: Some sections of a website might contain private or confidential information that you don’t want to appear in search results. By disallowing these sections in the robots.txt file, you can prevent search engines from indexing them.
Optimizing Crawl Budget: Search engines allocate a certain amount of resources, often referred to as a “crawl budget,” to each website. By using the robots.txt file to direct crawlers to the most important and relevant pages, you can ensure that the crawl budget is spent on indexing the most valuable content on your site.
Avoiding Duplicate Content Issues: Duplicate content can negatively impact SEO rankings. If you have multiple versions of the same content (e.g., printer-friendly versions, session IDs, etc.), you can use the robots.txt file to prevent search engines from indexing these duplicate pages.
Preventing Unwanted URLs: Sometimes, certain URLs generated by scripts or dynamic content may not be useful for search engines to index. You can use the robots.txt file to block these URLs from being crawled and indexed.
Improving Site Speed: Preventing search engines from crawling and indexing resource-intensive or unnecessary parts of your site can improve overall site speed and performance. This can have a positive impact on user experience and search rankings.
Avoiding Penalties: Using the robots.txt file correctly can help you avoid unintentional violations of search engine guidelines. If you accidentally expose sensitive or restricted content to search engines, it might lead to penalties or lowered rankings.
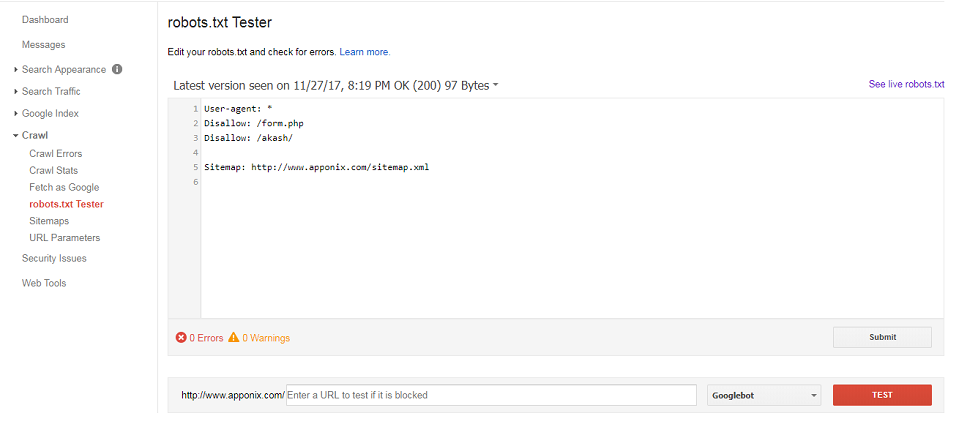
The robots.txt file is a complete text file used for giving instructions to the search engine spiders as to on which files it has to crawl and which files to avoid.
Create a robots.txt file using any text editor and save with extension .txt. Specify the xml sitemap’s absolute path in live robots.txt file for identifying crawler or spider (boot) fast.
You can give instructions to the search console (Webmaster Tool) by submitting the robots.txt file.

The Structure of robots.txt file:
User-agent:*
Allow
Here user-agent: * indicates it is applicable to all search engine agents and disallows this instruction to block all files inside.
Robots.txt is a text file that is uploaded to a website’s root directory (inside public html folder). The robots.txt file contains information as to which page to index or not to index by spiders.
All search engines support these extensions.
User-agent: *
Disallow: /
To allow everything:
User-agent: *
Allow: /
To block specific directories use:
User-agent: *
Disallow: /admin/
You can block individual search engine wise also
User-agent: Googlebot
Disallow:
If the domain is digitalakash.in, then the robots.txt URL should be like:
Note: The filename is case sensitive (it should be robots.txt)
https://www.digitalakash.in/robots.txt
How to use WhatsApp for Business
Benefits of robots.txt file:
Search engine | Field | User-agent |
| Baidu | General | baiduspider |
| Baidu | Images | baiduspider-image |
| Baidu | Mobile | baiduspider-mobile |
| Baidu | News | baiduspider-news |
| Baidu | Video | baiduspider-video |
| Bing | General | bingbot |
| Bing | General | msnbot |
| Bing | Images & Video | msnbot-media |
| Bing | Ads | adidxbot |
| General | Googlebot | |
| Images | Googlebot-Image | |
| Mobile | Googlebot-Mobile | |
| News | Googlebot-News | |
| Video | Googlebot-Video | |
| AdSense | Mediapartners-Google | |
| AdWords | AdsBot-Google | |
| Yahoo! | General | slurp |
| Yandex | General | yandex |